
Cannibalizzazione Keyword: Come Evitarla
La cannibalizzazione delle keyword, dall’inglese keyword cannibalization, è un fenomeno che affligge molti siti web. Nonostante sia davvero diffuso, ancora troppi proprietari di domini online non ne sono a conoscenza e soprattutto non sono in grado di affrontarlo nella maniera più corretta possibile.

I suoi effetti sul posizionamento organico di un sito possono essere rilevanti e inficiare il lavoro che è stato svolto su ciascuna delle pagine. Per questa ragione, è bene rivolgersi a un’agenzia web come Vanilla Marketing, quando si iniziano a vedere dei cali di traffico dovuti alla cannibalizzazione delle parole chiave.
Indice
Cannibalizzazione delle keyword: cos’è
Con questa espressione ci si riferisce alla presenza di due o più pagine, appartenenti al medesimo sito, che competono l’una con l’altra in una SERP riferita a una determinata query di ricerca. Ciò è dovuto a un intervento errato sulle risorse web, dal momento che quest’ultime sono state ottimizzate per la stessa o, peggio, per le stesse parole chiave.
Vediamo insieme un esempio nell’immagine riportata qua sotto, in cui per la keyword escursioni etna lo stesso sito compare con due diverse pagine:
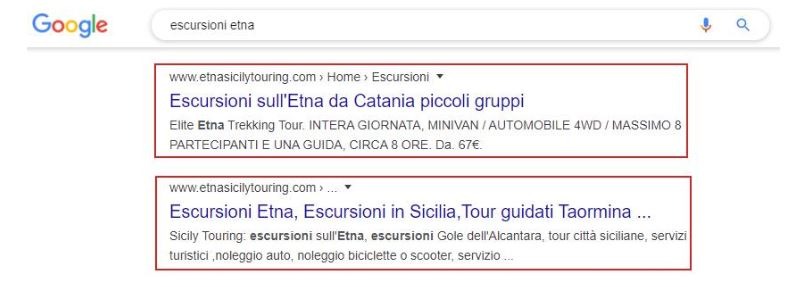
Tale problema può essere relativo sia alle pagine interne di un sito sia a quelle che compongono la sezione blog. Inoltre, la cannibalizzazione dei contenuti può anche colpire gli e-commerce. Se due prodotti possiedono delle caratteristiche, per cui è difficile distinguerli tramite il testo, è probabile che le corrispondenti schede prodotto si trovino a contendersi posizioni nei risultati di ricerca.
Altra situazione, che purtroppo si verifica molto frequentemente, è quella per cui un articolo del blog viene inavvertitamente ottimizzato per la medesima parola chiave per cui è stata implementata la scheda dell’articolo venduto. Le conversioni saranno penalizzate, poiché un contenuto informativo ha meno probabilità di convertire di uno che si trova già nella pagina del prodotto.
Perché si verifica
E’ bene sottolineare che la keyword cannibalization è una spina nel fianco di molti progetti online e, come è immaginabile, non è necessariamente legata a un comportamento volontario di colui che progetta il sito o di colui che crea i contenuti. La maggior parte delle volte tale criticità si manifesta a seguito dell’ideazione di un’architettura informativa non pienamente corretta.
Ordinare i contenuti del sito in sezioni troppo vicine da un punto di vista semantico aumenta le probabilità di assistere a una cannibalizzazione delle chiavi di ricerca. Un’ulteriore ragione è la creazione di contenuti ottimizzati per keyword che rispondono a un identico intento di ricerca.
Testi che puntano a posizionarsi per parole chiave uguali o per search intent simili possono causare tale fenomeno.
Quali sono le conseguenze
E’ evidente che tale criticità non è ben voluta da chi gestisce un sito web: nessuno vuole gareggiare contro se stesso. Inoltre, da un punto di vista SEO, la cannibalizzazione delle keyword determina una “dispersione” del valore riguardante i link esterni e la rilevanza delle parole chiave.
Altro fattore da prendere in considerazione, contemporaneamente all’emergere di tale difficoltà, è la riduzione del CTR organico, se confrontato con quello che la pagina potrebbe conseguire se non si trovasse a competere con un altro documento proveniente dallo stesso sito.
Il CTR, così come il traffico da sorgenti organiche, rappresenta una metrica a cui Google presta attenzione nello stabilire il ranking delle varie pagine dei domini. Ne deriva che un CTR basso influenzerà negativamente il posizionamento. In aggiunta, una percentuale di clic non ottimale condiziona in maniera negativa l’autorità generale del sito web.
La presenza di due o più pagine di un sito di proprietà in una SERP causa anche una ripartizione più netta e quindi più onerosa, in termini di sforzo da parte di Google, del Crawl Budget, ossia della quantità di URL che lo spider può e desidera scansionare. Rendendo la vita più difficile al Googlebot e facendogli analizzare pagine non necessarie, si potrebbe incorrere in posizionamenti al di sotto delle proprie aspettative.
Con la cannibalizzazione delle parole chiave viene creata confusione agli occhi di Google. Il suo compito di decidere quale sia la pagina, tra le due appartenenti al medesimo sito, con il contenuto di maggiore valore si complica. Ovviamente, il motore di ricerca non vedrà di buon occhio questo aspetto e, molto probabilmente, potrebbe abbassare il ranking di entrambe le pagine.
Anche il mio sito web è affetto da questo problema?
Oltre ai tool a pagamento come SEOZoom e Semrush che aiutano a individuare tale aspetto problematico, esistono anche dei modi totalmente gratuiti con cui verificare se il proprio progetto web ha delle pagine che entrano in competizione nella stessa SERP. Vengono in nostro soccorso gli operatori di ricerca avanzati forniti da Google.
Il più famoso è il comando site: che consente di osservare tutte le pagine del sito indicizzate dal motore di ricerca. Aggiungendo a questo comando la stringa “parola chiave” si possono identificare i contenuti posizionati per una specifica keyword.
Vi basterà digitare nella barra di ricerca i seguenti comandi:

Si può, inoltre, ricorrere all’operatore intitle: per individuare le parole chiave presenti nel tag title di una pagina. E’ sufficiente digitare nella barra di ricerca:

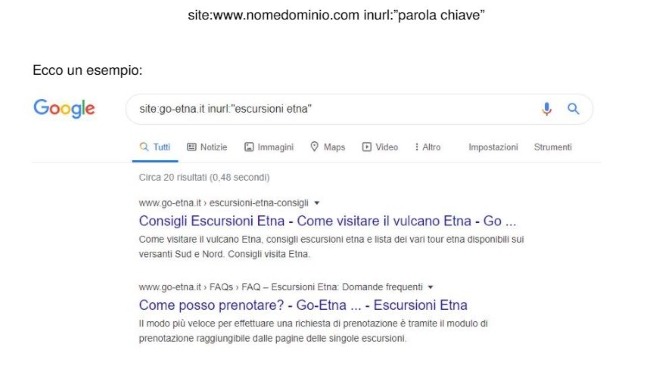
Infine, è possibile utilizzare anche il comando di ricerca avanzata inurl: con il fine di scovare le parole chiave presenti nei vari URL. L’operatore viene attivato digitando:
Risolvere la cannibalizzazione delle parole chiave
E’ fondamentale agire in maniera repentina e cercare di mettere in campo la strategia che meglio si adatta al proprio progetto web. Entriamo nel dettaglio dei metodi ai quali si può fare affidamento nell’eventualità in cui emerga un problema di cannibalizzazione dei contenuti.
Utilizzare i link interni
La prima soluzione è rappresentata dall’inserimento di link interni nelle pagine che trattano un argomento “vicino” a quello per cui è stata ottimizzata la pagina che si potrebbero definire “principale” o, entrando più nello specifico cornerstone content.
Facciamo subito un esempio che aiuti a chiarire il concetto: ipotizziamo che nel vostro blog abbiate precedentemente creato un articolo che ruota intorno alla parola chiave pignoramento. Scrivendo, in una fase successiva, un articolo ottimizzato per la keyword pignoramento immobiliare prima casa si dovrà inserire un link interno che rimandi all’articolo che ha come keyword principale “pignoramento”.
La parola “pignoramento” va scelta come anchor text del link interno, con l’obiettivo di incrementare il livello di coerenza tra le due pagine. Non è detto che il link debba essere posizionato per forza nel corpo del testo, ma può anche trovarsi nel breadcrumb.
Implementare il meta tag “noindex”
Operando in questa maniera, uno dei due contenuti, dopo essere stato scansionato, non sarà ricompreso da Google all’interno del suo immenso indice e quindi non comparirà nelle SERP. Tuttavia, questa indicazione può anche non essere seguita dal search engine. Ciò succede, ad esempio, se Google giudica l’altra pagina deindicizzata come di maggiore valore per gli utenti.
Usare il tag rel=canonical
Tale alternativa è particolarmente efficace se si ha intenzione di mantenere attive entrambe le pagine in competizione, evitando di richiedere al motore di ricerca di non indicizzare una delle due. Grazie all’implementazione del rel=canonical si indica a Google quale tra i due documenti è quello canonico, ossia quale deve considerare come l’originale.
E’ giusto, però, tenere presente che tale direttiva rivolta a Google non viene interpretata da quest’ultimo come obbligatoria: il motore di ricerca può sempre scegliere, di sua iniziativa, di mostrare la pagina che non abbiamo indicato come canonica.
Fondere le pagine
Un’altra via da seguire è quella di unire i due contenuti in un’unica pagina. Se si ritiene che le due risorse rispondano a un unico intento di ricerca, è bene farle congiungere, realizzando così un solo documento che si trovi a competere solo con concorrenti esterni. Una volta intrapresa questa strada, dovrete anche decidere se avvalervi di una delle due URL già esistenti oppure crearne una nuova di zecca.
Nel caso in cui si propenda per questa seconda opzione occorre effettuare gli adeguati redirect 301 al fine di salvaguardare la link juice ottenuta grazie ai link provenienti da altri siti.
Riottimizzare meta tag e contenuti
Modificando i principali meta tag interni a una pagina web e di fondamentale importanza per la SEO, come tag title, meta description, H1 e così via, riuscirete a focalizzarvi su un unico intento di ricerca. Agendo sul contenuto, evitate l’utilizzo di parole chiave che si riferiscano a search intent eterogenei e che possano indurre in confusione Google, dando così forma alla cannibalizzazione delle keyword.
All’opposto, cercate di far emergere il più possibile la parola chiave principale per la quale si è deciso di ottimizzare la pagina.
Curare la keyword research
Questo consiglio serve a prevenire più che a curare la keyword cannibalization. In fase di ricerca delle parole chiave è essenziale analizzare l’eventuale presenza, all’interno del proprio sito web, di pagine che già rispondano ai search intent che si vogliono intercettare. Nel caso in cui esistesse già questa tipologia di pagine è preferibile ottimizzare i contenuti già esistenti.
Se si decidesse di redigere contenuti inediti, c’è bisogno di fare attenzione al posizionamento di queste nuove risorse web. Infatti, esse potrebbero entrare in competizione con le pagine già presenti nel sito.
Un caso particolare: i progetti editoriali
Tutto ciò che è stato appena scritto, con particolare riguardo ai consigli su come evitare la cannibalizzazione delle parole chiave, si può applicare a molti siti, ma non a tutti. Pensiamo ai grandi giornali online come il Washington Post o il Guardian. Essi sfornano ogni giorno una quantità spropositata di articoli che, molto probabilmente, saranno colpiti dal problema di cui ci stiamo occupando.
E’ facilmente intuibile come i giornalisti non possano eseguire un’accurata ricerca delle parole chiave prima di scrivere l’articolo, perderebbero la “freschezza” della notizia. Per questo motivo, è necessario che gli autori in Rete siano in grado di scegliere titoli e intestazioni capaci di entrare nel dettaglio dell’articolo e cercare di differenziarsi il più possibile dagli altri pezzi presenti nella versione online del giornale.
Alcuni, inoltre, utilizzano anche dei sistemi automatici per generare i contenuti, come gli algoritmi che hanno il compito di estrarre dati da porzioni di testo di grandi dimensioni. Davanti a questa ipotesi, la chiave del successo risiede nella capacità di automatizzare il lavoro delle macchine affinché esse siano in grado di estrarre una breve descrizione dell’articolo e renderla unica e diversa da altri titoli presenti nel Web.
Conclusioni
Abbiamo visto cos’è la cannibalizzazione delle keyword e come è possibile evitarla seguendo le diverse indicazioni che sono state fornite. Rimane un’ultima cosa da dire: non sempre la keyword cannibalization è negativa. Può accadere che due pagine appartenenti allo stesso sito web che si trovino a competere sulla SERP di una query di ricerca occupino la prima e la seconda posizione. La situazione appena descritta è l’unica che non deve destare particolari preoccupazioni.
Solitamente, se una persona non clicca sul primo risultato, clicca sul secondo. Se, però, in seconda posizione c’è sempre un contenuto dello stesso sito, allora il CTR non subisce variazioni negative, anzi, ne beneficia. Ci sarà da intervenire se la situazione cambia e le posizioni si modificano. Allora, bisognerà trattare la cannibalizzazione dei contenuti con i metodi che sono stati elencati sopra.
Altri articoli che ti potrebbero interessare:
- Link building Cos’è, e a che cosa serve
- Consulenza Legale Online
- Web Hosting Sito sicuro e come proteggersi dai Malware
- Evoluzione dei siti web e del web design
- Cosa vendere online